Après les deux mini-extensions Murs et Maisons, voici une autre extension pour le jeu de société Carcassonne que j’ai réalisée, cette fois avec de nouvelles tuiles.
Les déserts
Matériel
- 16 nouvelles tuiles Terrain représentant des déserts
- 4 nouvelles tuiles Terrain représentant des déserts et montagnes
- 30 pions chameaux de 3 couleurs différentes : 10 blancs, 10 gris et 10 couleur bois
- un sac destiné à contenir les pions chameaux

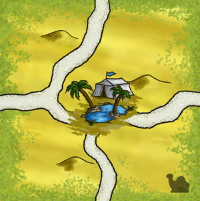
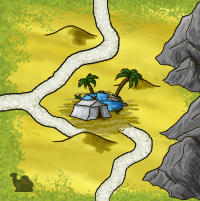
Mise en place
Mélanger les 16 nouvelles tuiles avec les autres tuiles Terrains.
Si vous jouez avec l’extension non-officielle intégrant les montagnes, ajouter également les 4 tuiles montagne.
Placer les pions chameau dans un sac qui constitue la « réserve de chameaux ».
Placement des tuiles Terrain
Les règles de placement des tuiles restent inchangées.
Si le placement de la tuile connecte une oasis avec une route incomplète occupée par au moins un partisan et aucun chameau, piocher au hasard un chameau de la réserve et le placer sur la route.
Si le placement d’une tuile prolonge une route contenant un ou plusieurs chameaux, le joueur ayant placé la tuile bénéficie d’un bonus pour chaque chameau présent. Pour que ce bonus se déclenche, il n’est pas nécessaire qu’un des partisans de ce joueur occupe la route. Le bonus déclenché par un chameau dépend de sa couleur :
- Chameau gris : le joueur gagne 3 points.
- Chameau blanc : le joueur bénéficie d’un tour double. S’il est déjà en train de jouer un tour double, il gagne 2 points à la place.
- Chameau couleur bois : le joueur pioche une tuile terrain et la place devant lui. Au début de ses prochains tours, il pourra choisir de jouer l’une des tuiles ainsi piochées à la place de piocher une tuile.
Placement des partisans
Lorsque vous placez une tuile contenant une pyramide, vous pouvez placer un partisan sur celle-ci à la place de le placer sur une autre structure présente sur la tuile.
Aucun partisan ne peut être placé sur le désert ni sur les oasis.
Si un partisan est placé sur une route incomplète connectée à une oasis et ne contenant aucun chameau, piocher au hasard un chameau de la réserve et le placer sur la route.
Évaluation des constructions complétées

Une pyramide est complétée lorsque les 12 tuiles qui l’entourent sont placées (deux dans chaque sens verticalement et horizontalement et une dans chaque sens en diagonale), la pyramide est complétée. Si un ou plusieurs partisans sont présents sur la pyramide, le ou les joueurs en ayant le plus grand nombre gagne 13 points plus 2 points supplémentaires par oasis présente dans les 13 tuiles de sa zone d’influence.
Lorsqu’une route contenant des chameaux est complétée, ceux-ci n’influent en aucune manière sur le décompte des points et retournent simplement dans la réserve.
Fin de partie et décompte final
En fin de partie les pyramides incomplètes sont évaluées de façon similaire aux abbayes : le ou les joueurs contrôlant la pyramide gagne un point pour chaque tuile présente dans sa zone d’influence (y compris la tuile pyramide elle-même).
Les chameaux et oasis n’ont aucune influence sur le décompte final.
Précisions et interactions avec d’autres extensions
Les embranchements de route sans obstacle (oasis ou autre) ne coupent pas la route (comme la tuile avec le puits dans Maires et Monastères).
Si l’effet d’un chameau blanc se déclenche en même temps que celui d’un bâtisseur (extension Marchands et Bâtisseurs) ou tout autre effet déclenchant un tour double, le joueur gagne deux points au lieu d’obtenir un second tour double.
Il est possible de placer un partisan sur une pyramide inoccupée à l’aide d’un portail magique (extension Princesse et Dragon).
Il est possible de placer un partisan sur une pyramide, occupée ou non, à l’aide d’un aéronef (mini-extension Les aéronefs).
Téléchargement des nouvelles tuiles
Les tuiles sont téléchargeables au format PDF (~41Mo). Ce fichier comporte l’ensemble des tuiles désert, celle de cette première partie constituent la page 1.

 : Mettez deux marqueurs +1/+1 sur la créature Vampire ciblée. » et «
: Mettez deux marqueurs +1/+1 sur la créature Vampire ciblée. » et «  : Exilez toutes les créatures non-Squelette. Mettez sur le champ de bataille un jeton de créature 2/2 noire Vampire pour chaque créature exilée de cette manière ».
: Exilez toutes les créatures non-Squelette. Mettez sur le champ de bataille un jeton de créature 2/2 noire Vampire pour chaque créature exilée de cette manière ».
 ). Pour la même raison les capacités restent assez simples. Vu que les vampires sont à la mode en ce moment, j'ai abandonné ma première idée des squelettes et fait deux capacités liées à ce peuple.
). Pour la même raison les capacités restent assez simples. Vu que les vampires sont à la mode en ce moment, j'ai abandonné ma première idée des squelettes et fait deux capacités liées à ce peuple.

 ) ce que j'ai utilisé mais je sais que j'y ai appliqué plusieurs effets par-dessus.
) ce que j'ai utilisé mais je sais que j'y ai appliqué plusieurs effets par-dessus. Puis bon, à vrai dire je pense pas que grand monde s'en souciera réellement
Puis bon, à vrai dire je pense pas que grand monde s'en souciera réellement 


