Ce matin, je me suis dit que comme parmi mon groupe d'amis, j'étais seul connecté Guild Wars 2, j'allais faire mes objectifs quotidiens JcJ. Là, j'ai constaté que quelque chose avait changé sans figurer dans les notes de mises à jour (ou alors, je l'ai raté) : on ne peut plus choisir quelle équipe on rejoint lorsqu'on rejoint une partie. Sur le principe, je comprends assez bien qu'il s'agit d'empêcher le joueur qui rejoint la partie de se mettre dans l'équipe qui a le plus de points, la renforçant du coup et creusant l'écart, ce qui semblerait assez raisonnable. Sauf que du coup ça rend encore plus saillant un gros vice de conception sur lequel je pensais écrire un article depuis un moment, sans prendre le temps de le faire : un gros foirage dans l'utilisation des couleurs.
Comme dans beaucoup de jeux vidéos, des codes couleurs permettent de différencier les alliés des ennemis. En l'occurrence, tout ce qui est allié est indiqué dans une nuance de vert ou bleu et ce qui est ennemi en rouge (plus du blanc ou jaune pour les non-hostiles, mais attaquables). Tout ça marche très bien lorsqu'on joue en JcE où tout est clair dans l'ensemble. Par contre, ça se corse grandement quand on passe en JcJ. Dans ce dernier mode, deux équipes de joueurs s'affrontent avec divers objectifs, chaque équipe étant identifiée par une couleur. Et fort logiquement, ces couleurs sont... le bleu et le rouge !
Normal, me direz-vous, comme ça, c'est cohérent avec le reste. Oui, mais non. Parce que le bleu identifie l'une des équipes, mais pas forcément la vôtre. Vous pouvez très bien vous retrouver dans l'équipe rouge. En principe, à ce stade, vous devriez commencer à saisir le problème, mais pour bien préciser les choses, voici ce que ça donne dans le cas de l'activité "Bagarre de barils" (où des barils de bière sont balancés périodiquement au milieu de la carte, l'équipe gagnante étant celle qui en aura rapporté le plus dans sa "base") :
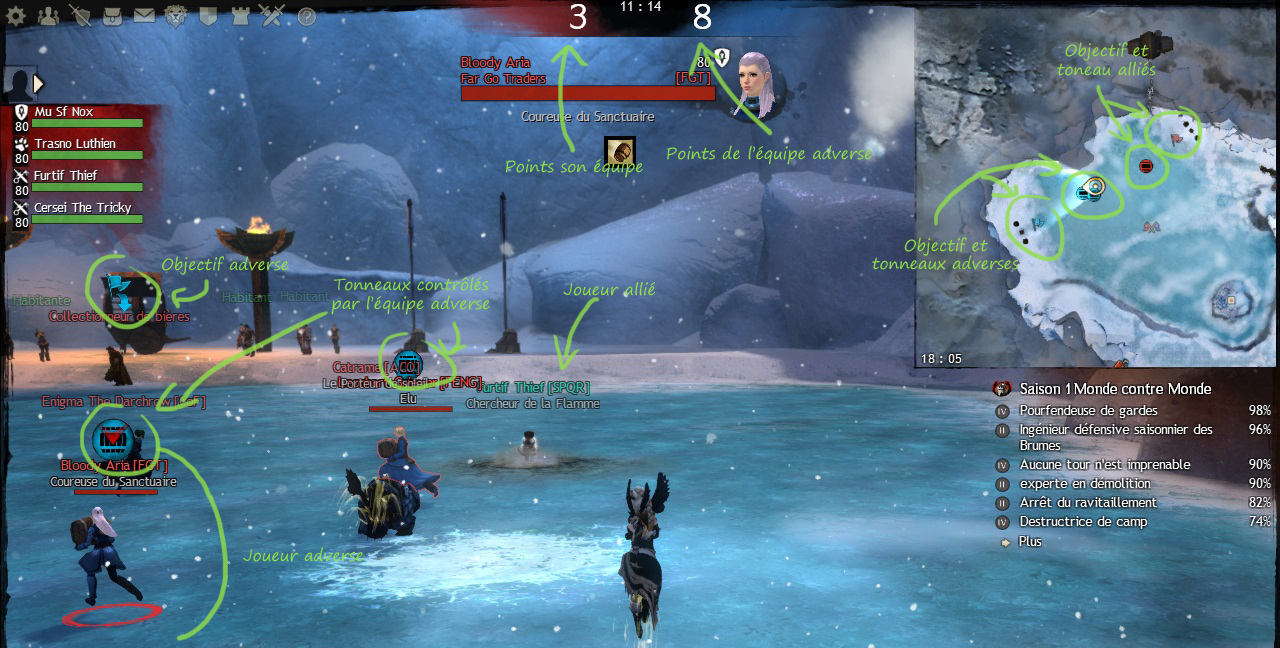
Je ne sais pas pour vous, mais quand je vois ça, j'ai toujours du mal à bien cerner ce qui représente mon équipe et ce qui représente l'équipe adverse...
J'ai beau tourner ça dans tous les sens, je n'arrive pas à comprendre comment ils en sont arrivés là. Parce qu'on ne parle pas d'un petit projet de fin d'étude, là, on parle d'un des MMORPG les plus joués du moment, vendu à plusieurs millions d'exemplaires, d'un jeu qui a pris des années à développer par une équipe conséquente, d'un jeu sorti depuis maintenant bientôt un an et demi et qui est régulièrement mis à jour.
Dans ces conditions, il semble impensable qu'il n'y ait pas un jour un des membres de l'équipe qui ait lancé une phrase du style "Dites, je pense à un truc là, on aurait pas un problème avec les codes couleurs ?". Et franchement, j'aimerais vraiment savoir ce qu'ont bien pu répondre les autres pour qu'au final la décision soit prise de laisser les choses en l'état. Parce que là, je dis chapeau, justifier un truc aussi absurde, c'est une belle performance !
Et en attendant, je vais arrêter de jouer en JcJ parce qu'autant avant, je faisais en sorte de toujours être dans l'équipe bleue histoire d'avoir un truc cohérent, autant là vu qu'on peut plus choisir...
EDIT 21/12/2013 : Bon apparemment la suppression du choix de l'équipe ne devait être qu'un bug, parce qu'il a été rétabli depuis... Donc ça redevient jouable. Mais ça ne change rien au problème initial des codes couleur !
